最重要的问题是与标准 Ryzen 和 EPYC CPU 相比,这些处理器究竟发生了什么变化。有人怀疑它们是重新贴了个标签的 AMD 处理器,这是完全不对的——我们可以通过 Linux 内核更新提供的不同加密引擎来反驳这一点。而且我们还发现了其他差异。
从总体上来看,我们可以确定,核心布局是相同的,缓存大小,TLB(Translation Lookaside Buffer 转换后备缓冲区) 大小和端口分配都相同——在此基础级别上没有差异。海光 CPU 仍然为 L1 高速指令缓存提供64 KB 4路,为 L1 高速数据缓存提供32 KB 8路,为 L2 高速缓存提供512 KB 8路,为 L3 高速缓存提供8 MB 16路。这些和 Zen 1 核心是相同的。 转换后备缓冲区条目如下:
- L1D + L1I: 4K/2M/1G 64-entry
- L2D: 4K 1536-entry 6-way, 2M 1536-entry 3-way, no 1G
- L2I: 4K/2M 1024-entry 8-way, no 1G
L1 的内存访问时间为4个周期,L2 的为12个周期,L3 的为37-40个周期。记忆潜伏期在284-307个周期内测量。
L1 读取速度的测量约为每个时钟32个字节(总计805 GB/s,每个内核约100 GB/s),而写入速度测量的每个时钟约为16个字节(总计408 GB/s,每个内核约51 GB/s) )。 8核的 DDR4 内存速度使读取速度为38.5 GB/s,写入速度为35.8 GB/s。
加密上的变化
对于加密更改,Linux 内核更新中详细介绍了这些更改。更新围绕 AMD 的虚拟化功能或 SEV(Secure Encrypted Virtualization 安全加密虚拟化) 的安全加密进行。通常,对于 EPYC 处理器,SEV 由 AMD 定义的加密协议控制,在这种情况下为 RSA(Rivest–Shamir–Adleman),ECDSA(Elliptic Curve Digital Signature Algorithm),ECDH(Elliptic-curve Diffie–Hellman),SHA(Secure Hash Algorithms) 和 AES(Advanced Encryption Standard)。为了生成正确的密钥,SEV 使用这些方法。但是,在海光 Dhyana 设计中,SEV 被构建为使用称为 SM2,SM3 和 SM4 的算法。
正如更新中所述,SM2 基于椭圆曲线密码学,并且需要其他私钥/公钥交换。SM3 是类似于 SHA-256 的哈希算法,SM4 是类似于 AES-128 的分组密码算法。为了支持这些算法所需的额外功能,这些命令已加入到 Linux 内核中。说明书中指出,这些算法已在海光 Dhyana Plus(可能是大型 CPU)处理器上成功测试过,也已在 AMD 的 EPYC CPU 上成功测试过。
减缓指令执行速度
我们能够确定的最大设计上的变更是指令吞吐量。我们认为 Dhyana Plus 和之前提到的 EPYC 之间没什么不同,并且我们做了额外的检查以确保我们的软件能够显示正确的数据,但只是故意将某些指令放慢了他们的执行速度。这里面有一些相当严肃的含义,尤其是取决于它何时在管道中发生。
我们认为情况是,为了让 AMD 导出其 SoC 设计,海光还必须共享与 CPU 解释指令的方式有关的微代码,并且还要放慢某些关键指令的执行速度(或完全禁用),以便合资公司继续和中国合作。
在我们的测试中,我们发现,尽管海光和 EPYC 之间的整数性能相似,但某些浮点指令(即 DIV 和 SQRT 运算)并未在海光 CPU 中进行流水线处理。这意味着吞吐量和延迟减少了。许多简单的 MMX / SSE(Streaming SIMD Extensions) 指令降低了吞吐量,以下表格列出了指令吞吐量差异:
| AnandTech | EPYC Naples | Hygon Dhyana |
|---|---|---|
| ADD/SUB | 2 per clock | 1 per clock |
| CMP/MULP* | 2 per clock | 1 per clock |
| ADDSUBP* | 2 per clock | 1 per clock |
| RCP*/RSQRT* | 1 per clock | 0.5 per clock |
| BLENDW | 3 per clock | 2 per clock |
| PMIN/MAX* | 3 per clock | 2 per clcok |
| PAND/ANDN/OR/XOR | 4 per clock | 2 per clock |
| MOVs | 4 per clock | 2 per clock |
所有这些指令对于基本任务都非常重要。通过限制这些指令的并行吞吐率,这意味着这些 CPU 无法计算并行化的代码,从而降低性能。
但是,最大的变化或许是服务器版“Dhyana Plus”和消费版“Dhyana”版本之间的差异。Dhyana Plus 大大减少了随机数生成的作用。关键指令 RDRAND 和 RDSEED 具有各种导致速度变慢或变快的原因。
RDRAND 指令比较如下:
| AnandTech | Zen 1 Desktop | Hygon Dhyana | Hygon Dhyana Plus |
|---|---|---|---|
| 16-bit | 1200 clocks | 1100 clocks | 800 clocks |
| 32-bit | 1200 clocks | 1100 clocks | 800 clocks |
| 64-bit | 2365 clocks | 2125 clocks | 1520 clocks |
RDSEED 指令比较如下:
| AnandTech | Zen 1 Desktop | Hygon Dhyana | Hygon Dhyana Plus |
|---|---|---|---|
| 16-bit | 1200 clocks | 1100 clocks | 12000 clocks |
| 32-bit | 1200 clocks | 1100 clocks | 12000 clocks |
| 64-bit | 2365 clocks | 2125 clocks | 27100 clocks |
看上图发现差异还是很大的,尤其是在 RDSEED 中。我们看到 RDSEED(用于生成随机数算法的种子生成)在服务器芯片上的速度慢了10倍以上,而用于实际基于硬件的随机数生成 RDRAND 则比标准 Ryzen 快——在服务器芯片上也是如此。有趣的是,在 Ryzen Mobile 和 Ryzen Desktop APU 上也看到了服务器芯片的 RDSEED 相同的延迟。
对于 RDRAND 指令,拥有更快的随机数生成器可以说明两件事:要么实际上更快,要么随机算法的周期性较低。例如:指向一个自我包装的算法。最好的伪随机数生成具有最大的周期性,因此在这种情况下,很快我们就能得出 RDRAND 指令结论,周期性较低,从而导致生成质量较低的随机数。
对于 RDSEED 指令,它慢10倍的情况有点不同。RDSEED 指令从主板上的各种传感器中获取信息,并输出一个随机值来初始化 RDRAND——每个周期只能调用一次。较慢的 RDSEED 要么意味着它从更多源获取数据,要么是故意放慢了。
实际上,RDRAND 和 RDSEED 可以在我们的 Dhyana Plus 系统的 BIOS 中启用或禁用。
有趣的是,此菜单称为“Moksha 通用选项”。 Moksha 通常是与“启蒙”或“释放”相关的词。这要么是一个有趣的文字游戏,要么是有人无视上下文从古汉英词典中找的词。
关于 AVX 和 AVX2 的性能,即使 CPU 标识着支持 AVX 和 AVX2,但尝试实际测量这些指令时却失败了——在我们的指令转储中,它们被列为“支持的,已禁用”。关于所支持的功能,Zen 1 通常将 AESNI,SHA,CLMUL,FMA4,BMI 和 BMI2 列为支持的指令——海光 CPU 不支持这些指令。
对于 AES 之类的东西,我们做了一个基准测试,这些 CPU 不支持 AES,意味着性能大打折扣:
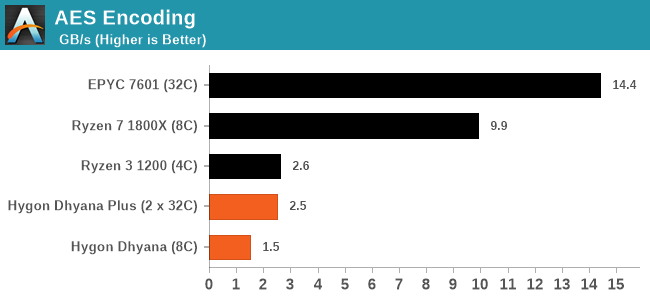
还有一点需要注意,通过探测寄存器来查找 AMD CPU 功耗的典型手段在这里也失效了。似乎完全从 CPU 中删除了。
(未完待续…)